Google Research acaba de presentar en NeurIPS 2025 un paper que podría cambiar nuestra comprensión fundamental de cómo funcionan los modelos de lenguaje: Nested Learning revela que los LLMs no son simplemente capas apiladas, sino sistemas complejos de optimización multinivel donde cada componente —incluyendo los optimizadores— actúa como un módulo de memoria que aprende a comprimir información a diferentes escalas temporales. Las implicaciones para la reputación algorítmica corporativa y el futuro del GEO son profundas.
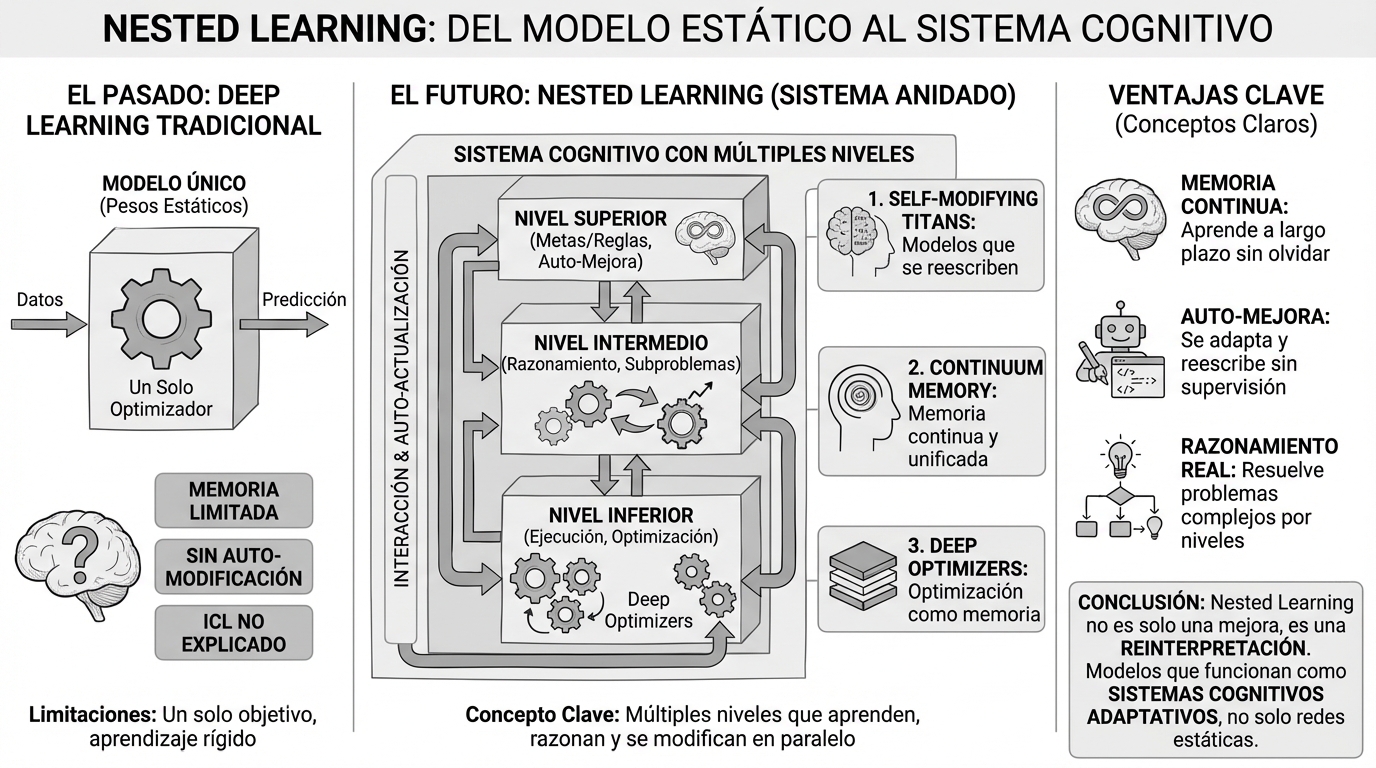
Nested Learning representa un cambio de paradigma: de modelos estáticos con un solo optimizador a sistemas cognitivos adaptativos con múltiples niveles que aprenden, razonan y se auto-modifican en paralelo.
Artículo científico analizado: Behrouz, A., Razaviyayn, M., Zhong, P., & Mirrokni, V. (2025). Nested Learning: The Illusion of Deep Learning Architectures. 39th Conference on Neural Information Processing Systems (NeurIPS 2025). Google Research.
La amnesia anterógrada algorítmica de los LLMs actuales
Para entender la importancia del paper "Nested Learning: The Illusion of Deep Learning Architectures" de Ali Behrouz, Meisam Razaviyayn, Peiling Zhong y Vahab Mirrokni (Google Research, 2025), los autores comienzan con una analogía provocadora: los Large Language Models actuales sufren de una condición análoga a la amnesia anterógrada—un trastorno neurológico donde una persona no puede formar nuevas memorias a largo plazo después del inicio del trastorno, aunque las memorias existentes permanecen intactas.
Esta analogía describe perfectamente la arquitectura de los LLMs post-entrenamiento: su conocimiento está limitado al contexto inmediato que cabe en su ventana de contexto (memoria de trabajo de corto plazo) o al conocimiento congelado en los parámetros MLP que almacenan el "largo pasado" anterior al fin del pre-entrenamiento. Entre ambos extremos no existe consolidación: la información en el contexto nunca impacta los parámetros de memoria a largo plazo (las capas feedforward), haciendo que el modelo sea incapaz de adquirir nuevo conocimiento o habilidades genuinas, a menos que la información siga almacenada en memoria de corto plazo (atención).
Como señalan Behrouz et al. (2025, p. 3):
"El diseño de los LLMs, y más específicamente los backbones basados en Transformers, sufre de una condición similar después de la fase de pre-entrenamiento. Es decir, la información provista en el contexto nunca impacta los parámetros de memoria a largo plazo (ej., capas feedforward), y por tanto el modelo no es capaz de adquirir nuevo conocimiento o habilidad, a menos que la información aún esté almacenada en la memoria de corto plazo (ej., atención)."
Este diagnóstico tiene implicaciones directas para la reputación algorítmica: cuando tu marca, producto o servicio aparece en el contexto de un LLM, esa información no se consolida automáticamente en su memoria persistente. La única forma de lograr presencia duradera es estar presente en el conocimiento pre-entrenado—un proceso opaco, no controlable directamente, y que se actualiza con poca frecuencia.
Inspiración neurocientífica: Cómo el cerebro consolida memorias
Para resolver esta limitación, los autores se inspiran en neurociencia y estudios sobre neuroplasticidad—la capacidad del cerebro de cambiar en respuesta a nuevas experiencias, memorias, aprendizaje e incluso daño (Pascual-Leone et al., 2005; Johnston, 2009). Investigaciones recientes demuestran que la formación de memoria a largo plazo involucra al menos dos procesos de consolidación distintos pero complementarios (Goto et al., 2021; Frey & Morris, 1997; Yang et al., 2024):
- Consolidación "online" (consolidación sináptica): Ocurre inmediatamente o poco después del aprendizaje, incluso durante la vigilia. Es cuando nuevas trazas de memoria inicialmente frágiles se estabilizan y comienzan a transferirse desde almacenamiento de corto a largo plazo.
- Consolidación "offline" (consolidación sistémica): Durante el sueño, patrones recientemente codificados se reproducen—durante sharp-wave ripples (SWRs) en el hipocampo, coordinados con sleep spindles corticales y oscilaciones lentas—fortaleciendo y reorganizando la memoria y soportando la transferencia a sitios corticales (Ji & Wilson, 2007; Peyrache et al., 2009; Foster & Wilson, 2006).
El paper de Behrouz et al. (2025) se enfoca en el primer proceso: consolidación de memoria como proceso online. La clave está en reconocer que el cerebro humano opera con múltiples escalas temporales simultáneas: diferentes regiones cerebrales actualizan su información a frecuencias distintas, desde ondas delta lentas (0.5-4 Hz) hasta ondas gamma rápidas (30-100 Hz), permitiendo procesamiento jerárquico de información a diferentes niveles de abstracción.
Nested Learning: Descomponiendo arquitecturas en problemas de optimización anidados
El paradigma de Nested Learning (NL) propuesto por Behrouz et al. (2025) representa una ruptura conceptual con la visión tradicional de deep learning. En lugar de ver un modelo de IA como una secuencia de capas apiladas que procesan información de forma feed-forward, NL revela que los modelos son sistemas integrados de problemas de optimización multinivel y anidados, cada uno con su propio "flujo de contexto" y frecuencia de actualización.
Memoria asociativa como fundamento universal
El framework comienza redefiniendo todos los componentes de un modelo—desde las redes neuronales hasta los optimizadores—como sistemas de memoria asociativa. Siguiendo la literatura de neuropsicología (Okano et al., 2000; Terry, 2017), los autores distinguen claramente entre memorización y aprendizaje:
"La memoria es una actualización neuronal causada por una entrada, y el aprendizaje es el proceso para adquirir memoria efectiva y útil." (Behrouz et al., 2025, p. 4)
Formalmente, dado un conjunto de claves K ⊆ ℝdk y valores V ⊆ ℝdv, la memoria asociativa es un operador M : K → V que aprende el mapeo optimizando:
M* = arg minM L̃(M(K); V)
Mientras el operador en sí es una memoria y el mapeo actúa como proceso de memorización, adquirir tal operador efectivo basado en datos es un proceso de aprendizaje. Crucialmente, este proceso puede interpretarse también como compresión de datos: la red M(·) comprime los mapeos en sus parámetros, representándolos en un espacio de menor dimensionalidad.
Descomposición arquitectónica: Del MLP simple a Transformers
Los autores demuestran paso a paso cómo las arquitecturas tradicionales son instancias de este paradigma. Consideremos el entrenamiento de un MLP de 1 capa (parametrizado con W) en un dataset Dtrain = {x1, ..., x|Dtrain|} con gradient descent:
Wt+1 = Wt − ηt+1 ∇yt+1ℒ(Wt; xt+1) ⊗ xt+1
Behrouz et al. (2025, p. 5) reformulan esto como un problema de optimización de memoria asociativa:
Wt+1 = arg minW ⟨W xt+1, ∇yt+1ℒ(Wt; xt+1)⟩ + (1/2ηt+1)||W − Wt||22
Aquí, ut+1 = ∇yt+1ℒ(Wt; xt+1) es interpretado como una "señal de sorpresa local" (LSS) en el espacio de representación—cuantificando el desajuste entre la salida actual y la estructura que el objetivo ℒ(·;·) impone. Por tanto, el entrenamiento se traduce como un proceso de adquirir memoria efectiva que mapea muestras de datos a sus señales LSS.
Cuando reemplazan gradient descent con gradient descent con momentum, emerge una estructura de 2 niveles:
Wt+1 = Wt − mt+1
mt+1 = arg minm −⟨m, ∇Wtℒ(Wt; xt+1)⟩ + ηt+1 ||m − mt||22
Esto revela que gradient descent con momentum es un proceso de optimización de 2 niveles: el nivel interno (m) aprende a comprimir gradientes en sus parámetros, y el nivel externo actualiza los pesos lentos (Wt) con el valor de la memoria de nivel interno. Esta perspectiva conecta directamente con Fast Weight Programs (FWPs) (Schmidhuber, 1992), donde el proceso de actualización de pesos es la red lenta cuyo peso momentum es generado por una red rápida.
Arquitecturas como sistemas multinivel
La descomposición se extiende a arquitecturas completas. Cuando entrenan linear attention (Katharopoulos et al., 2020) con gradient descent, obtienen una estructura de 2 niveles donde:
- El nivel externo (también conocido como "proceso de entrenamiento") optimiza las capas de proyección (Wk, Wv, Wq) con gradient descent.
- El nivel interno optimiza la memoria interna Mt con gradient descent para comprimir el contexto.
Crucialmente, cada memoria asociativa tiene su propio proceso de optimización y flujo de gradientes. No hay backpropagation entre niveles: en la optimización de parámetros de nivel externo no hay gradiente respecto a M(·), y en el nivel interno las proyecciones se consideran congeladas.
Como señalan Behrouz et al. (2025, p. 7):
"Cada componente tiene su propio problema de optimización y por tanto contexto. Aunque optimizamos el objetivo interno del componente con optimizadores basados en gradientes, la declaración anterior es equivalente a tener flujo de gradientes exclusivo para cada componente en el modelo."
Definición formal: Frecuencia de actualización y jerarquía de niveles
Para ordenar los componentes en niveles, los autores introducen el concepto de frecuencia de actualización (Behrouz et al., 2025, Definition 2): para cualquier componente A (parametrizado como pesos aprendibles o no parametrizado como bloque de atención), su frecuencia fA es su número de actualizaciones por unidad de tiempo (donde una unidad = un paso de actualización sobre un punto de datos).
Dados dos componentes A y B, definimos A ≻ B (A es más rápido que B) si:
- fA > fB, o
- fA = fB pero el cómputo del estado de B en tiempo t requiere el cómputo del estado de A en tiempo t.
Basándose en este operador, los componentes se ordenan en "niveles" donde: (1) componentes en el mismo nivel tienen la misma frecuencia de actualización, y (2) cuanto mayor el nivel, menor su frecuencia. Esta jerarquía permite que modelos sean representados como sistemas de múltiples escalas temporales, similar a las ondas cerebrales en neurociencia.
Implicación #1: Los optimizadores son módulos de memoria profunda
Uno de los hallazgos más sorprendentes del paper es demostrar que optimizadores bien conocidos como Adam y SGD con Momentum son en realidad módulos de memoria asociativa que comprimen gradientes pasados. Esta no es una reinterpretación metafórica: Behrouz et al. (2025) lo demuestran matemáticamente.
Consideremos SGD con momentum:
Wi+1 = Wi + mi+1
mi+1 = αi+1mi − ηt∇ℒ(Wi; xi)
Si asumimos αi+1 = 1, el término momentum puede verse como el resultado de optimizar el siguiente objetivo con gradient descent (Behrouz et al., 2025, p. 7):
minm ⟨m ∇ℒ(Wi; xi)⊤, I⟩
Esto revela que momentum es un meta-módulo de memoria que aprende a memorizar gradientes del objetivo en sus parámetros. El término momentum no es solo un truco de optimización: es una memoria que comprime el pasado.
Deep Optimizers: Más allá del momentum tradicional
Esta perspectiva habilita diseñar "Deep Optimizers" más expresivos. Behrouz et al. (2025, pp. 7-8) proponen varias extensiones:
- Asociación más expresiva: Momentum tradicional es una memoria sin valores (value-less), con poder expresivo limitado. Introduciendo un parámetro de valor vi = Pi, el momentum minimiza:
minm ⟨m ∇ℒ(Wi; xi)⊤, Pi⟩
resultando en momentum precondicionado. Esto significa que momentum es una memoria que aprende a comprimir mapeos entre Pi y el término de gradiente, donde Pi puede contener información del Hessiano. - Objetivos más expresivos: Usar pérdida de regresión ℓ2(·) en lugar de dot-product permite actualización basada en delta-rule (Prados & Kak, 1989), permitiendo que memoria (momentum) gestione mejor su capacidad limitada:
mi+1 = (αi+1I − ∇ℒ(Wi; xi)⊤ ∇ℒ(Wi; xi)) mi − ηtPi∇ℒ(Wi; xi)
- Memoria más expresiva: En lugar de momentum como capa lineal (matriz-valued), usar un MLP profundo. Esto permite que momentum capture funciones no lineales de gradientes pasados, aumentando su capacidad de aprendizaje. Los autores llaman a esta variante Deep Momentum Gradient Descent (DMGD).
- Outputs no lineales: Añadir no-linealidades sobre el output del momentum, como σ(·) = Newton-Schulz(·) (Higham, 2008). Cuando m(·) es lineal y σ(·) es Newton-Schulz iterativo, el optimizador resultante es equivalente a Muon optimizer (Jordan et al., 2024).
Más allá del simple backpropagation
Behrouz et al. (2025, pp. 8-9) también reformulan el proceso de backpropagation/pre-training como memoria asociativa. El gradient descent estándar:
Wt+1 = Wt − ηt+1∇ytℒ(Wt; xt) ⊗ xt
es equivalente a un paso de gradient descent en:
minW ⟨W xt, ∇ytℒ(Wt; xt)⟩
Esta formulación ignora dependencias entre puntos de datos como xt. Para formular un optimizador más poderoso que considere estas dependencias (crítico cuando el optimizador actúa en espacio de tokens, donde tokens no son independientes), usan regresión L2:
minW ||W xt − ∇ytℒ(Wt; xt)||22
Esto resulta en una nueva variante de gradient descent:
Wt+1 = Wt(I − xtxt⊤) − ηt+1∇ytℒ(Wt; xt) ⊗ xt
Los autores usan este optimizador como el optimizador interno de su arquitectura HOPE.
Implicación #2: Continuum Memory System y aprendizaje continuo genuino
La segunda contribución principal es el Continuum Memory System (CMS), que generaliza la visión tradicional binaria de memoria corto plazo/largo plazo. Inspirándose en la observación de que el cerebro opera con múltiples frecuencias de actualización simultáneas, Behrouz et al. (2025, p. 9) proponen:
"Desde la perspectiva de NL, el pre-entrenamiento es la fase donde el nivel más externo del módulo de aprendizaje se actualiza sobre su flujo de contexto limitado. Por consiguiente, en el setup continuo, tal fase de pre-entrenamiento también se actualiza raramente con el tiempo, y por tanto su almacenamiento de conocimiento correspondiente necesita actualizarse raramente con el tiempo."
Arquitectura del Continuum Memory System
El CMS se formaliza como una cadena de bloques MLP: MLP(f1)(·), ..., MLP(fk)(·), cada uno asociado con un tamaño de chunk C(ℓ) := maxℓ C(ℓ) / fℓ. Dada entrada x = {x1, ..., xT}, el output de la cadena es:
yt = MLP(fk)(MLP(fk-1)(...MLP(f1)(xt)))
donde los parámetros del ℓ-ésimo bloque MLP, θ(fℓ), se actualizan cada C(ℓ) pasos:
θ(fℓ)i+1 = θ(fℓ)i − Σit=i−C(ℓ) η(ℓ)t f(θ(fℓ)t; xt) si i ≡ 0 (mod C(ℓ))
donde f(·) es el componente de error de un optimizador arbitrario (ej., ∇ℒ(θ(fℓ)t; xt) en gradient descent).
El Transformer convencional es un caso especial de esta formulación donde k = 1. La interpretación clave es que los parámetros θ(fℓ)t son responsables de comprimir su propio contexto en sus parámetros, actuando como representantes del conocimiento abstracto de su contexto a diferentes escalas temporales.
Implicación #3: HOPE y modelos auto-modificables
Combinando el CMS con una arquitectura de secuencia auto-referencial basada en Titans (Behrouz et al., 2024) y la variante de gradient descent que considera dependencias de datos, los autores presentan HOPE—un módulo de aprendizaje que demuestra capacidades emergentes de aprendizaje continuo.
Resultados experimentales en language modeling
HOPE fue evaluado en tres escalas (340M, 760M, y 1.3B parámetros) sobre benchmark de language modeling (WikiText, LAMBADA) y tareas de common-sense reasoning (PIQA, HellaSwag, WinoGrande, ARC-easy, ARC-challenge, SIQA, BoolQ).
Los resultados (Behrouz et al., 2025, Table 1, p. 10) muestran que HOPE:
- A escala 760M parámetros / 30B tokens, alcanza accuracy promedio de 52.26% en downstream tasks, superando a Transformer++ (48.69%), RetNet (48.46%), DeltaNet (48.97%), TTT (47.32%), y acercándose a Samba (51.08%) y Titans-LMM (51.56%).
- A escala 1.3B parámetros / 100B tokens, HOPE obtiene 57.23% accuracy promedio, superando a Transformer++ (52.25%), RetNet (52.02%), DeltaNet (52.14%), Samba (54.00%) y quedando muy cerca de Titans-LMM (56.82%).
- En perplexity de language modeling (WikiText, LAMBADA), HOPE muestra competitividad sólida: 15.11/11.63 ppl a 1.3B escala, cercano a Titans-LMM (15.60/11.41) y superando significativamente a Transformers (18.53/18.32).
Como concluyen los autores (Behrouz et al., 2025, p. 10):
"HOPE demuestra muy buen desempeño a través de todas las escalas y benchmark tasks, superando tanto a Transformers como a recientes redes neuronales recurrentes modernas, incluyendo Gated DeltaNet y Titans. Comparando HOPE con Titans y Gated DeltaNet, podemos ver que cambiar dinámicamente las proyecciones de key, value y query basándose en el contexto, así como un módulo de memoria profunda, puede resultar en un modelo con menor perplexity y mayor accuracy en resultados de benchmark."
Implicaciones para la reputación algorítmica y estrategias GEO
Los hallazgos de Nested Learning tienen consecuencias directas y profundas para quienes trabajan en reputación algorítmica y Generative Engine Optimization (GEO):
1. Frecuencia de actualización y persistencia de información
Si futuros modelos adoptan arquitecturas basadas en NL con Continuum Memory Systems, la información que una marca provee tendrá diferentes probabilidades de consolidación según a qué nivel de frecuencia resuene. Información que coincida con frecuencias de actualización de niveles superiores (menos frecuentes, pero más persistentes) tiene mayor probabilidad de consolidarse en memoria a largo plazo del modelo.
Implicación práctica: Contenido fundamental, perenne, de alta autoridad (como whitepapers técnicos, definiciones canónicas, guías comprehensivas) debería estructurarse para ser comprimido eficientemente en memorias de baja frecuencia. Contenido táctico, temporal, o muy específico puede residir en niveles de alta frecuencia (contexto inmediato).
2. Compresión de contexto y señales E-E-A-T
Behrouz et al. (2025) demuestran que los modelos aprenden comprimiendo su propio flujo de contexto. Esto significa que contenido estructurado con señales claras de E-E-A-T (Experiencia, Expertise, Autoridad, Confianza)—como autoría verificable, citaciones a fuentes primarias, datos empíricos, consistencia con conocimiento establecido—se comprime más eficientemente y persiste mejor en memoria asociativa del modelo.
Como discutimos en nuestra guía de AEO, los LLMs favorecen contenido exhaustivo, estructurado en formato pregunta-respuesta, con datos concretos y actualizado. NL explica por qué: este tipo de contenido minimiza la "señal de sorpresa local" (LSS) del modelo—el desajuste entre output actual y estructura que el objetivo impone—facilitando su compresión en parámetros.
3. Memoria asociativa y mapeos clave-valor consistentes
Architecturas futuras basadas en NL priorizarán fuentes que establecen mapeos clave-valor consistentes y repetibles entre queries y respuestas. Esto refuerza la importancia estratégica de:
- Contenido en formato Q&A explícito: FAQs, HowTos, guías estructuradas con Schema.org markup.
- Consistencia terminológica: Usar vocabulario estable y definido para conceptos clave asociados a tu marca.
- Topic Clusters coherentes: Familia de contenidos interconectados que refuerzan mapeos similares query→respuesta.
Como vimos en nuestro análisis sobre medición GEO con IA Listening, la métrica crítica es el "share of voice": frecuencia con que tu marca es mencionada en respuestas a consultas relevantes. NL sugiere que esta frecuencia depende de qué tan eficientemente tu contenido se comprime en memoria asociativa del modelo.
4. Consolidación selectiva y calidad sobre cantidad
Similar a cómo el cerebro humano consolida selectivamente memorias de alta calidad durante el sueño (Yang et al., 2024), futuros LLMs con CMS consolidarán selectivamente información según su "fitness" para compresión. Esto amplifica exponencialmente la importancia de autoridad y confiabilidad.
Información de fuentes de baja autoridad, inconsistente, o contradictoria con conocimiento establecido generará alta LSS (señal de sorpresa local) y será menos probable de consolidarse. Como analizado en nuestro post sobre por qué la IA ama Reddit, aunque plataformas UGC como Reddit históricamente recibieron muchas citas (debido a volumen y diversidad), actualizaciones recientes de ChatGPT (septiembre-octubre 2025) redujeron citas a Reddit/Wikipedia del ~60% al ~10-20%, priorizando "entidades verificadas y confiables" (Actualización de Entidades, octubre 2025).
5. Aprendizaje continuo y ventanas de consolidación
Si modelos futuros implementan aprendizaje continuo genuino vía consolidación online (el enfoque de HOPE), existirán ventanas críticas de consolidación—momentos donde información del contexto se transfiere a memoria a largo plazo. Empresas necesitarán:
- Monitorear eventos de consolidación: Detectar cuándo modelos actualizan sus parámetros de memoria a largo plazo.
- PR digital estratégico durante ventanas: Intensificar presencia en fuentes de alta autoridad durante períodos de consolidación.
- Medición dinámica de reputación: Herramientas de IA Listening que tracken cambios en share of voice post-consolidación.
6. Optimización para diferentes niveles de abstracción
Dado que NL revela que modelos procesan información a múltiples niveles de abstracción simultáneamente, estrategias GEO efectivas necesitarán contenido optimizado para diferentes niveles:
| Nivel | Frecuencia | Tipo de Contenido | Ejemplo |
|---|---|---|---|
| Nivel 1 (más rápido) | Alta frecuencia, contexto inmediato | Respuestas tácticas, datos específicos, FAQs | "¿Cuál es el precio actual de [producto]?" |
| Nivel 2 (intermedio) | Frecuencia media, conocimiento episódico | Guías prácticas, casos de uso, comparativas | "¿Cómo implementar [tecnología] en [industria]?" |
| Nivel 3 (más lento) | Baja frecuencia, conocimiento semántico | Definiciones canónicas, frameworks conceptuales, investigación fundamental | "¿Qué es [concepto fundamental] y por qué importa?" |
Contenido para Nivel 3 (memoria a largo plazo, baja frecuencia de actualización) requiere máxima autoridad: papers peer-reviewed, citaciones académicas, definiciones ampliamente adoptadas. Este contenido define tu reputación algorítmica fundamental.
El futuro que viene: De LLMs estáticos a sistemas de aprendizaje continuo
Nested Learning no es solo un framework teórico: es una hoja de ruta hacia la próxima generación de modelos de IA. Como señalan Behrouz et al. (2025, p. 2):
"NL sugiere un camino (una nueva dimensión al deep learning) para diseñar algoritmos de aprendizaje más expresivos con más 'niveles', resultando en capacidades de in-context learning de orden superior."
Las implicaciones son profundas:
- Modelos que se auto-mejoran: Architecturas como HOPE aprenden a modificar su propio algoritmo de actualización, permitiendo mejora continua sin re-entrenamiento completo.
- In-context learning de orden superior: Con más niveles de optimización anidada, modelos desarrollarán capacidades emergentes de aprendizaje más sofisticadas—no solo aprender del contexto, sino aprender cómo aprender del contexto.
- Consolidación selectiva y economía de la atención: Modelos con CMS consolidarán selectivamente información según calidad y relevancia, amplificando el "winner-takes-all effect" donde fuentes de máxima autoridad capturan share of voice desproporcionado.
Preparándose para el cambio de paradigma
Para empresas y profesionales de GEO, la transición hacia modelos basados en NL requiere acción estratégica inmediata:
- Auditoría de contenido multinivel: Evalúa tu contenido actual según los tres niveles de abstracción. ¿Tienes conocimiento fundamental (Nivel 3) con máxima autoridad? ¿O solo contenido táctico (Nivel 1)?
- Inversión en autoridad verificable: Incrementa señales E-E-A-T: autoría experta, revisión por pares, citaciones académicas, Schema.org markup comprehensivo. Como vimos en nuestros benchmarks GEO 2026, la brecha entre líderes y rezagados en cada sector se está ampliando.
- Medición dinámica con IA Listening: Implementa monitoreo continuo de tu share of voice en respuestas de IA. Herramientas especializadas como IA Listening permiten auditar sistemáticamente menciones, posición, tono y cobertura multi-plataforma.
- Estrategia de Topic Clusters coherentes: Construye familias de contenido interconectado que refuerzan mapeos consistentes query→respuesta. Esto facilita compresión en memoria asociativa de modelos NL.
- Presencia en fuentes de consolidación: Diversifica tu presencia más allá de tu propio sitio. Como discutimos en nuestra guía práctica de AEO, aparecer en Forbes, LinkedIn, sitios de noticias establecidos, y directorios de alta autoridad aumenta probabilidad de consolidación en memoria a largo plazo de modelos.
Conclusión: La reputación algorítmica en la era de Nested Learning
El paper "Nested Learning: The Illusion of Deep Learning Architectures" de Behrouz, Razaviyayn, Zhong y Mirrokni (Google Research, 2025) representa un cambio fundamental en cómo entendemos—y por tanto, cómo optimizamos para—los modelos de lenguaje de gran escala.
Al revelar que los LLMs son sistemas de problemas de optimización multinivel y anidados, cada uno comprimiendo su propio flujo de contexto en memoria asociativa a diferentes frecuencias temporales, NL explica fenómenos previamente misteriosos como el emergence de in-context learning, y más importante, traza el camino hacia modelos con aprendizaje continuo genuino.
Para la reputación algorítmica corporativa, las implicaciones son claras: en un futuro donde modelos consolidan selectivamente información según su fitness para compresión—priorizando autoridad verificable, consistencia, y mapeos clave-valor estables—la estrategia GEO evoluciona de "aparecer en respuestas" a "ser consolidado en memoria a largo plazo del modelo".
Esta no es una transición que ocurrirá en años: Google Research está publicando estos avances ahora, en NeurIPS 2025. La ventana para construir fundamentos sólidos de reputación algorítmica—contenido de máxima autoridad, señales E-E-A-T robustas, presencia en fuentes de consolidación, medición sistemática—está abierta. Quienes actúen estratégicamente hoy capturarán share of voice desproporcionado cuando modelos de próxima generación con CMS comiencen a desplegar.
Como demuestran los casos de éxito GEO que analizamos, la diferencia entre líderes y rezagados no es incremental: es exponencial. En la era de Nested Learning, esa brecha solo se ampliará.
Referencias
- Behrouz, A., Razaviyayn, M., Zhong, P., & Mirrokni, V. (2025). Nested Learning: The Illusion of Deep Learning Architectures. 39th Conference on Neural Information Processing Systems (NeurIPS 2025). Google Research.
- Behrouz, A., Zhong, P., & Mirrokni, V. (2024). Titans: Learning to memorize at test time. arXiv preprint arXiv:2501.00663.
- Foster, D. J., & Wilson, M. A. (2006). Reverse replay of behavioural sequences in hippocampal place cells during the awake state. Nature, 440(7084), 680-683.
- Goto, A., Bota, A., Miya, K., Wang, J., Tsukamoto, S., Jiang, X., ... & Hayashi, Y. (2021). Stepwise synaptic plasticity events drive the early phase of memory consolidation. Science, 374(6569), 857-863.
- Higham, N. J. (2008). Functions of matrices: theory and computation. SIAM.
- Ji, D., & Wilson, M. A. (2007). Coordinated memory replay in the visual cortex and hippocampus during sleep. Nature neuroscience, 10(1), 100-107.
- Johnston, M. V. (2009). Plasticity in the developing brain: implications for rehabilitation. Developmental disabilities research reviews, 15(2), 94-101.
- Jordan, K., Jin, Y., Boza, V., Jiacheng, Y., Cecista, F., Newhouse, L., & Bernstein, J. (2024). Muon: An optimizer for hidden layers in neural networks.
- Katharopoulos, A., Vyas, A., Pappas, N., & Fleuret, F. (2020). Transformers are rnns: Fast autoregressive transformers with linear attention. In International conference on machine learning (pp. 5156-5165). PMLR.
- Okano, H., Hirano, T., & Balaban, E. (2000). Learning and memory. Proceedings of the National Academy of Sciences, 97(23), 12403-12404.
- Pascual-Leone, A., Amedi, A., Fregni, F., & Merabet, L. B. (2005). The plastic human brain cortex. Annu. Rev. Neurosci., 28(1), 377-401.
- Peyrache, A., Khamassi, M., Benchenane, K., Wiener, S. I., & Battaglia, F. P. (2009). Replay of rule-learning related neural patterns in the prefrontal cortex during sleep. Nature neuroscience, 12(7), 919-926.
- Prados, D. L., & Kak, S. C. (1989). Neural network capacity using delta rule. Electronics Letters, 25(3), 197-199.
- Schmidhuber, J. (1992). Learning to control fast-weight memories: An alternative to recurrent nets. Neural Computation.
- Terry, W. S. (2017). Learning and memory: Basic principles, processes, and procedures. Routledge.
- Yang, W., Sun, C., Huszár, R., Hainmueller, T., Kiselev, K., & Buzsáki, G. (2024). Selection of experience for memory by hippocampal sharp wave ripples. Science, 383(6690), 1478-1483.